 “新狗”AlphaGo Zero的水平已經超過之前所有版本的AlphaGo。在對陣曾贏下韓國棋手李世石那版AlphaGo時,AlphaGo Zero取得了100:0的壓倒性戰績。
倫敦當地時間10月18日18:00(北京時間19日01:00),AlphaGo再次登上世界頂級科學雜志——《自然》。
一年多前,AlphaGo便是2016年1月28日當期的封面文章,Deepmind公司發表重磅論文,介紹了這個擊敗歐洲圍棋冠軍樊麾的人工智能程序。
今年5月,以3:0的比分贏下中國棋手柯潔后,AlphaGo宣布退役,但DeepMind公司并沒有停下研究的腳步。倫敦當地時間10月18日,DeepMind團隊公布了最強版AlphaGo ,代號AlphaGo Zero。它的獨門秘籍,是“自學成才”。而且,是從一張白紙開始,零基礎學習,在短短3天內,成為頂級高手。 團隊稱,AlphaGo Zero的水平已經超過之前所有版本的AlphaGo。在對陣曾贏下韓國棋手李世石那版AlphaGo時,AlphaGo Zero取得了100:0的壓倒性戰績。DeepMind團隊將關于AlphaGo Zero的相關研究以論文的形式,刊發在了10月18日的《自然》雜志上。
“AlphaGo在兩年內達到的成績令人震驚。現在,AlphaGo Zero是我們最強版本,它提升了很多。Zero提高了計算效率,并且沒有使用到任何人類圍棋數據,”AlphaGo之父、DeepMind聯合創始人兼CEO 戴密斯·哈薩比斯(Demis Hassabis)說,“最終,我們想要利用它的算法突破,去幫助解決各種緊迫的現實世界問題,如蛋白質折疊或設計新材料。如果我們通過AlphaGo,可以在這些問題上取得進展,那么它就有潛力推動人們理解生命,并以積極的方式影響我們的生活。”
不再受人類知識限制,只用4個TPU
AlphaGo此前的版本,結合了數百萬人類圍棋專家的棋譜,以及強化學習的監督學習進行了自我訓練。
在戰勝人類圍棋職業高手之前,它經過了好幾個月的訓練,依靠的是多臺機器和48個TPU(谷歌專為加速深層神經網絡運算能力而研發的芯片)。
AlphaGo Zero的能力則在這個基礎上有了質的提升。最大的區別是,它不再需要人類數據。也就是說,它一開始就沒有接觸過人類棋譜。研發團隊只是讓它自由隨意地在棋盤上下棋,然后進行自我博弈。值得一提的是,AlphaGo Zero還非常“低碳”,只用到了一臺機器和4個TPU,極大地節省了資源。
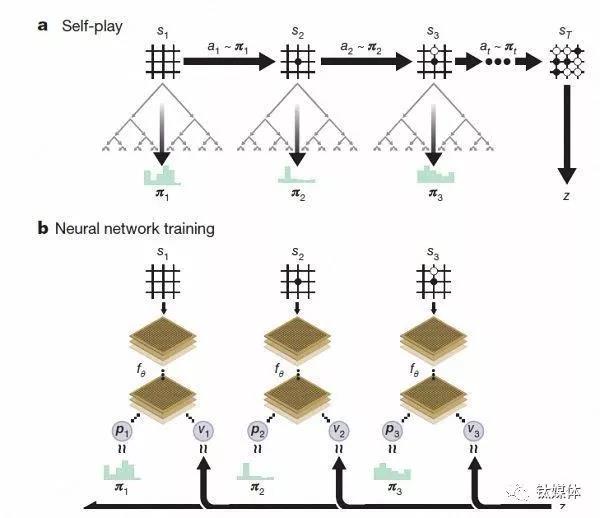
AlphaGo Zero強化學習下的自我對弈。經過幾天的訓練,AlphaGo Zero完成了近5百萬盤的自我博弈后,已經可以超越人類,并擊敗了此前所有版本的AlphaGo。DeepMind團隊在官方博客上稱,Zero用更新后的神經網絡和搜索算法重組,隨著訓練地加深,系統的表現一點一點地在進步。自我博弈的成績也越來越好,同時,神經網絡也變得更準確。 AlphaGo Zero習得知識的過程“這些技術細節強于此前版本的原因是,我們不再受到人類知識的限制,它可以向圍棋領域里最高的選手——AlphaGo自身學習。” AlphaGo團隊負責人大衛·席爾瓦(Dave Sliver)說。
據大衛·席爾瓦介紹,AlphaGo Zero使用新的強化學習方法,讓自己變成了老師。系統一開始甚至并不知道什么是圍棋,只是從單一神經網絡開始,通過神經網絡強大的搜索算法,進行了自我對弈。
隨著自我博弈的增加,神經網絡逐漸調整,提升預測下一步的能力,最終贏得比賽。更為厲害的是,隨著訓練的深入,DeepMind團隊發現,AlphaGo Zero還獨立發現了游戲規則,并走出了新策略,為圍棋這項古老游戲帶來了新的見解。
自學3天,就打敗了舊版AlphaGo
除了上述的區別之外,AlphaGo Zero還在3個方面與此前版本有明顯差別。
AlphaGo-Zero的訓練時間軸首先,AlphaGo Zero僅用棋盤上的黑白子作為輸入,而前代則包括了小部分人工設計的特征輸入。
其次,AlphaGo Zero僅用了單一的神經網絡。在此前的版本中,AlphaGo用到了“策略網絡”來選擇下一步棋的走法,以及使用“價值網絡”來預測每一步棋后的贏家。而在新的版本中,這兩個神經網絡合二為一,從而讓它能得到更高效的訓練和評估。
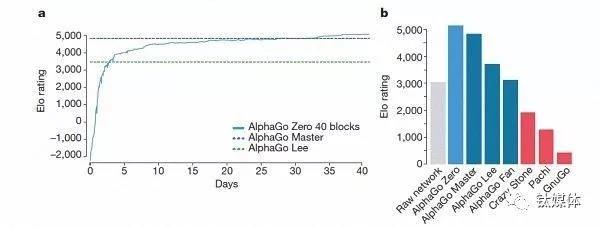
第三,AlphaGo Zero并不使用快速、隨機的走子方法。在此前的版本中,AlphaGo用的是快速走子方法,來預測哪個玩家會從當前的局面中贏得比賽。相反,新版本依靠地是其高質量的神經網絡來評估下棋的局勢。 AlphaGo幾個版本的排名情況。據哈薩比斯和席爾瓦介紹,以上這些不同幫助新版AlphaGo在系統上有了提升,而算法的改變讓系統變得更強更有效。
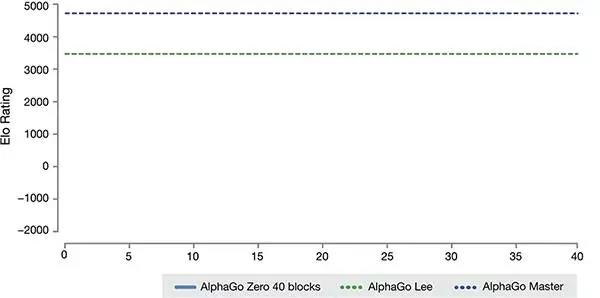
經過短短3天的自我訓練,AlphaGo Zero就強勢打敗了此前戰勝李世石的舊版AlphaGo,戰績是100:0的。經過40天的自我訓練,AlphaGo Zero又打敗了AlphaGo Master版本。“Master”曾擊敗過世界頂尖的圍棋選手,甚至包括世界排名第一的柯潔。 圖為DeepMind AlphaGo項目首席研究員大衛·席爾瓦(David Silver,左)與首席執行官德米斯·哈比斯(Demis Hassabis)
席爾瓦繼續稱:“在每場對弈結束后,AlphaGo Zero實際上都訓練了一個新的神經網絡。它改進了自己的神經網絡,預測AlphaGo Zero自己的棋路,同時也預測了這些游戲的贏家。當AlphaGo Zero這樣做的時候,實際上會產生一個更強大的神經網絡,這將導致‘玩家’進行新的迭代。因此,我們最終得到了一個新版AlphaGo Zero,它比之前的版本更強大。而且隨著這個過程不斷重復,它也可以產生更高質量的數據,并用于訓練更好的神經網絡。”
“新狗”AlphaGo Zero的未來
通過數百萬次自我對弈,AlphaGo從零開始掌握了圍棋,在短短幾天內就積累起了人類幾千年才有的知識。但AlphaGo Zero也發現了新的知識,發展出打破常規的策略和新招,與它在對戰李世石和柯潔時創造的那些交相輝映,卻又更勝一籌。
這些創造性的時刻給了我們信心:人工智能會成為人類智慧的增強器,幫助我們解決人類正在面臨的一些嚴峻挑戰 。盡管才剛剛發展起來,AlphaGo Zero已經走出了通向上述目標的關鍵一步。對于希望利用人工智能推動人類社會進步為使命的DeepMind來說,圍棋并不是AlphaGo的終極奧義,他們的目標始終是要利用AlphaGo打造通用的、探索宇宙的終極工具。
AlphaGo Zero的提升,讓DeepMind看到了利用人工智能技術改變人類命運的突破。他們目前正積極與英國醫療機構和電力能源部門合作,提高看病效率和能源效率。同時類似的技術應用在其他結構性問題,比如蛋白質折疊、減少能耗和尋找新材料上,就能創造出有益于社會的突破。
|